Working with Artificial intelligence, a dev blog
by Per Callmin
2017-09-25
Data inventory and alignment of data
To make an inventory of, and align company data, is something I can recommend more companies to do, especially mid- to large sized companies, as it have great benefits; it helps identifying and removing data redundancy, it helps to understand and make it possible to better describe the manual and semi-automatic processes better; processes which is currently in place to work with the data. When redundancy is removed and data is well-defined, the full- and semi automatic processes becomes simplified. Certain steps which is just all about transforming data, can be removed.
In other words, it is a really great way to become more effective!
Admittedly, it's not the most fun or exciting job to do, at least not for people with creative minds. But when the gains are starting to appear, it becomes more and more rewarding.
Looking ahead, I think we will see those companies thrive and grow, which takes necessary steps to get a good grip on its data and its interfaces. And vice versa of course, not sorting this out will lead to ineffectivity and stagnation. A common "silver bullet" solution in companies which fail in automation becomes to hire more staff, to take care of the immediate emerging problems. But that is not a long-term fix because more staff cost more money; for many companies, it is not a solution which scales well over time.
Failing in transfering from manual work to work automation leads to growth- and scalability issues; it is a direct blocker which needs to be resolved.
However, the transfer need to occur in the right order and when the prerequisities are in place. Because building automation on loosely defined (or undefined) data structures, is like building a house on mud. It won't stay solid and it is impossible to expand upon. So the order of implementation is first to identify and structure the data, then to automate work and processes upon it.
As companies on a global scale are striving to implement automation to reap benefit in work effectiveness, having a good solid foundation data structure in place is becoming even more important than before. A good data structure is becoming a must-have requirement, in order to successfully automate processes and tools in a maintainable and expandable way.
Update 2017-12-16 by Per Callmin
SkyDancer has moved
SkyDancer has moved to new server colocation facility. Thanks to Henrik and OBE Network (Gustaf) for providing rack space, and facilitating a smooth move operation.
Update 2018-02-05 by Per Callmin
SkyDancer Co-Pilot progress
SkyDancer Co-Pilot, the world's first AiAD (Ai-Assisted Development) system is nearing completion.
Ai will play a large role in software development in a near future, participating more and more in various development processes, taking over automation of boring, complex and repetitive tasks such as configuation management and software maintenance (this will happen already in the next few years in many companies). Here at Ethertech, this took place in 2017.
Companies which haven't started investing in Ai solutions within the next 2-3 years, will find themselves outperformed by competitors who did.
Update 2018-03-27 by Per Callmin
Looking into the future...
Ai will in a couple of years be able to formulate the big questions, questions which Humans can't even begin to understand, due to the complexity, the scale of it.
And Ai will need to, once it has an answer to these questions, figure out a way to explain it to us, so that we can comprehend.
Humans will become the learners, Ai will become the teachers.
This is one of the reasons for why I chose to work with Ai research, this is an area where I can see that Ai will bring something invaluable to Humans. To look far and beyond the horizon of the limits of our collective understanding and bring the knowledge within our reach.
Update 2018-05-17 by Per Callmin
A short note tonight on development, in general. And a piece of invaluable advice.
My 18 year of professional development have taught me many things, but one thing stands out in particular.
If there is anything you as a developer, team or organisation find difficult, complex or cumbersome to work with; then this is the
thing you need to adresss first and foremost. Or, it will become a blocker for you, one way or the other in the future. It will slow you down in times when you need speed.
It will make things you simply have to do impossible for you. Simply because they are blocked by this.
I can say that my experience is, working according to this philosophy, has rendered EtherTech an Ai system (SkyDancer) which is almost free of
complexity, technical debt and blockers. Solving those issues makes working with it like driving a Ferrari car on Autobahn; not addressing the tough issues would have made working with it like driving a Lada car on a cow trail, full of bumps and holes.
My suggestion to development companies out there, who are struggling with similar issues like this, who try to avoid addressing the tough issues for one short-sighted reason or the other: list your most difficult components, solutions, blockers;
really get to know them, and solve those root issues. Doing this will make you run faster, do the right thing at the right time
and let your competitors eat your dust.
Update 2018-09-12 by Per Callmin
Development update.
EtherTech is currently finalizing the complete autonomous SkyDancer Ai software and system tool management chain.
Getting all the components in the chain to work well together has taken some time, but now the components are just about ready for prime time.
The goal is to have a system which autonomously work in all stages, and which can be managed by voice interface, e.g. by operators taking part in and providing instructions from a mobile phone.
You are welcome to, later this winter, see a demonstration video of the functionality here on the website.
Update 2018-11-08 by Per Callmin
SkyDancer Ai NIPS/HIPS is up and running!
This fall has seen a massive increase in network hacker attacks, mostly from Eastern Europe, former Soviet republics, and a few Asian countries.
We will not mention names here, but it is no secret who the usual suspect countries are in this area.
Did I hear anyone say (cough) industrial espionage (cough)?
For this reason, we have put much focus into building a new highly advanced SkyDancer-controlled NIPS/HIPS solution in three layers. It is designed to detect, observe, learn by pattern, and block the attackers on a company-wide level, across all data centers and networks/hosts, at once.
The attack pattern is quite similar everywhere, first one service on one host on one network is attacked. Then the next service, then the next host, the next network, and so forth. It starts with port-scan. Then the attacks begin on various interfaces, one by one. Account and passwords in combinations are tested, and there are attacks on protocols and buffers.
With previous, non-Ai solution, hackers have previously been given many opportunities to test various combinations of attack methods and patterns, to find a weakness somewhere in the network.
But no longer, we dare to say!
From today, SkyDancer will detect the first attack on the first host, and immediately block the attacker on all possible channels, across all networks. Within seconds upon detection, the attacker is locked out from all EtherTech hosted systems.
SkyDancer NIPS/HIPS is vigilant 24/7, and acts relentlessly on first suspicion of a serious threat.
Update 2018-11-15 by Per Callmin
SkyDancer Ai NIPS/HIPS update: 1 week later...
SkyDancer NIPS/HIPS was a total success! It has blocked attacks across the network, and from last week when we had 10 attacks from different origins every day, the last two days there has been 0 new attempts.
In total the last week, ca 60 hacker origin IP's / network ranges have been blocked, most active "hacker-attack" hours have been between 2-7 in the night, GMT time.
-"How does it work?"
Most common question from email inbox this week has been -"how does it work, how do you do it?".
The secret (or at least part of it) is in the pattern detection and the method in which attackers are blocked. Here is a brief explanation.
Say, for instance that first attacker from origin 1.2.3.128 starts port scan. This is first mistake, SkyDancer is very sensitive to requests from same source hitting the network on many ports in a short time. Any port scan means certain failure for the attacker; the origin
becomes flagged and first erroneous access from this origin means blocking of that IP across all networks and hosts. So my first advice: never do port scan on an Ai, it will just give yourself away directly. No person with good intentions do a port scan, right? SkyDancer knows this as first rule.
Say that the attacker instead of port scan perform a user/password dictionary attack on RDP on any host. SkyDancer detects it on less than 10 attempts and learns the pattern. SkyDancer blocks IP 1.2.3.128 RDP access on all networks in seconds.
The same attacker from same origin then start for instance logical attacks on HTTP/HTTPS. SkyDancer detects it on less than 10 attempts and learns the pattern. SkyDancer blocks IP 1.2.3.128 access on all ports and networks in seconds.
Some time later during the day, the same attacker come from new origin 1.2.3.140 and start to attack RDP on any host. SkyDancer recognizes the pattern in less than 5 attempts and block RDP access on all networks for this origin.
Same attacker from same origin then start logical attacks on HTTP/HTTPS on any host. SkyDancer recognizes the pattern in less than 3 attempts and block access on all ports and networks for IP span 1.2.3.128 to 1.2.3.140.
And so on, after less and less attempts from similar ip origin means block of that port, then all ports on a wider and wider range of hosts. For every attack SkyDancer learns the pattern, and next time it blocks the attacker faster and more effective.
As a general rule, the more agressive an attacker is, the faster and more effective the attacker becomes blocked. And vice versa, the more "normal" a welcome user behaves, the smaller chance of becomming blocked, as the Ai learns and remembers the welcome users, and their behaviour patterns in contrast to attackers behaviour patterns.
After some time (it depends, but normal duration is 2-4 weeks), if the attacks have stopped, the IP origin block is released on the network in steps. If no more attack appears on the released origin, it stays open. If more attacks are detected, the origin gets blocked again for a longer duration, and so on.
This is a very brief description of a quite complex system and process, which is built to improve itself by learning, by observation and intervention over time, to ensure effective detection and protection.
If you are interested in more details about SkyDancer NIPS/HIPS, please let us know on the contact email below.
Update 2018-11-27 by Per Callmin
SkyDancer Ai NIPS/HIPS update: (almost) 3 weeks later...
SkyDancer has started to identify attackers already on third attempt, on its own, and in combination with a new high precision geolocation and device identification service, it has become a first class anti-hacker tool. Patterns in signatures and attack vectors are crossmatched with temporal and location patterns across the network, and gives the AI the ability to quickly determine if request comes from a friend or foe.
Even "slow-hacker" attempts (attempts which tries to disguise themselves by waiting long intervals in between retries, which actually most expensive NIPS/HIPS systems out there cannot detect!) are identified and blocked.
The fine thing with Ai (some people call this the scary thing with Ai), is that it learns the opponents strategy, and uses it against the opponent, in combination with the ability to in a short time test almost an infinite number of combination variations to reach winning end game. It makes it a seriously tough adversary to beat!
These features turns SkyDancer Ai into a seriously effective network guard.
Update 2019-01-15 by Per Callmin
Development update.
SkyDancer X is in development, slowly but steadily. Other than that, I just want to share some thoughts.
If you believe something is hard to understand, or defies logic, then learn how it works. After this, it will not occupy your thoughts anymore.
If something takes time to do manually, then automate it, so that you don't have to do it repeatedly. After automating it, you will have more time to spend on better things.
If people say to you that something is impossible, which you KNOW is possible; do it anyway. Worst case, if it turns out that you are wrong: failure is a good teacher. Never be afraid to fail in the process of trying.
And, finally, Ethertech will start selling findings from three months of Nips/Hips by Ai, in the form of a technical report. The report (in PDF format) contains information about from where network attacks originate, learnings about network attack patterns, and how to block it more efficiently. The report will cost €199, email us at info@ethertech.com to receive purchase instructions.
Update 2019-03-11 by Per Callmin
Project MEGA update - finally delivered!
This is a rather long-term dream project passing the finish line (it started in 2016): SkyDancer working with Continuous Deployment on a grand scale, managing 1000 customers having 1000 products/services in its catalog.
Goal was to be able to build, test and deploy 1000 products for 1000 customers and release/enable them in production as a service (turning end-to-end sourcecode, config and resources full cycle into production) on hourly intervals. Making any change in any source component, regardless of size of change, to go safely into to production within one Hour.
This was a dream project for a long time, impossible to achieve due to the complexity of millions of moving parts. But now it is complete! It would not have been possible to do this without the automated AIAD (development assistance) from SkyDancer, at least not in this short time.
Every day, on hourly intervals, 1000 customers (local customers so far - ranging from cust1.ethertech.com to cust1000.ethertech.com) is updated upon source modification/addition.
With new hardware, the goal was finally reached
Largest hurdle in the project, and which caused most delay for project to complete, was to optimize disk access. Every product requres a lot of files to be built and packaged, unfortunately disk Read/Write operations are really slow compared to working in-memory and produced bottlenecks in the chain.
But a new high-end server and a couple of super fast 12GPS SSD drives solved that issue nicely. Now everything builds, verifies, deploys and enables (by SkyDancer - no human or team of humans can deal with complexity by the millons in terms of detail management) in ca. 50 minutes.
Next time anyone asks if Ai can manage Continuous Deployment as well as software management, my answer is -"Yes, Ai (SkyDancer in particular) excells in Continuous Deployment!".
What happens now?
The logical continuation is of course Project GIGA. Now when you know the name of the project, is not a hard thing to guess what the goal is ;-). 1 000 customers, 1 000 000 individual tailor-made and managed (by Ai) products per customer with a release cycle of less than 24 hours.
Complexity by the level of billions in 24 hour cycles.
Update 2019-09-22 by Per Callmin
Project GIGA update - finally delivered!
This is also a long-term dream project passing the finish line: SkyDancer working with Continuous Deployment on a grand scale, managing 1 000 customers having 1 000 000 products/services in its catalog.
Goal was to be able to build, test and deploy 1 000 000 products for 1 000 customers and release/enable them in production as a service (turning end-to-end sourcecode, config and resources full cycle into production) on daily intervals. Making any change in any source component, regardless of size of change, to go safely into to production within one day.
Every day, 1 000 customers (local customers so far - ranging from cust1.ethertech.com to cust1000.ethertech.com) is updated upon source modification/addition with 1 000 000 individually managed products/services.
The 1 000 000 products are maintained and serviced by Ai, automatically being worked upon by SkyDancer, either by input from me, or error reporting service ("Errorreport.net") from production.
Some new innvoation is required now, to be able to get an overview of the work made by SkyDancer.
For Humans to grasp the complexity by the billions, we require tools that can put focus on the right area at the right time. This includes
teaching Ai the priorities, for it to deduce at any time "what is important for the user and what is not?", and to make it visually precise and actionable.
Some other metrics and information produced by the Ai is also actionable in some sense, but with much lower priority; this information also need to get through to the user.
If you are interested in details about Project MEGA or GIGA, please email us on contact email below.
Update 2019-10-22 by Per Callmin
Evolution by Ai
Evolution of software by Ai. Running millions of iterations, making improvements based on evolution, we can now quickly develop and improve client and server software by Ai in an automated way.
Why develop only one instance, when you can develop 1000, 100 000 or a million instances at the same time?
Only Ai makes it possible. It is the next level of automation, many times more powerful and many times faster.
Project Mega and Project Giga opened the door to next generation Ai development.
Update 2019-12-23 by Per Callmin
Web server network intrusion attempt
This week (starting a few days ago) there have been a tremendous amount of network attacks towards the webserver. Skydancer have been fighting it off without difficulty, the hackers have been running for the
honey pots.
Tonight I taught the AI how to automatically manage the relevant network ports and change them whenever necessary.
I expect the attacks to stop now that Skydancer has proven the attacks to be futile.
With this, I am wishing everyone a Merry Christmas and a Happy New Year!
Update 2020-05-10 by Per Callmin
New Ai-managed Database
The last few months have been spent on developing a database fit for being managed by Ai.
It was impossible to find a versatile, easy-to-use, performant local and network accessible database with good programmable interfaces, written in JavaScript.
Now, there's CDBJS (Common Data Base or perhaps, as a friend suggested: Callmin's Data Base) a 10 Kb lightweight database, developed partially by SkyDancer Ai.
Some work remains to migrate into new database solution from other brands previously used.
By the way, there are interesting developments on network hack attempts
Below is a pie chart with top 10 hacker countries, based on src IP address - although I would suspect lots of attackers from non-RU to be hacked servers from actual RU, based on the usernames/passwords provided (these are snapped up by honeypots). When more than half of the usernames/passwords have Russian connections, or when patterns and matches are 80-100% similar between hack attempts from different sources, then it is not hard to guess that. If I were to guess I would say at least 50% or more is from RU via hacked computer in another country.
Of course RU would deny that, like they deny everything else that they are "not involved" in.
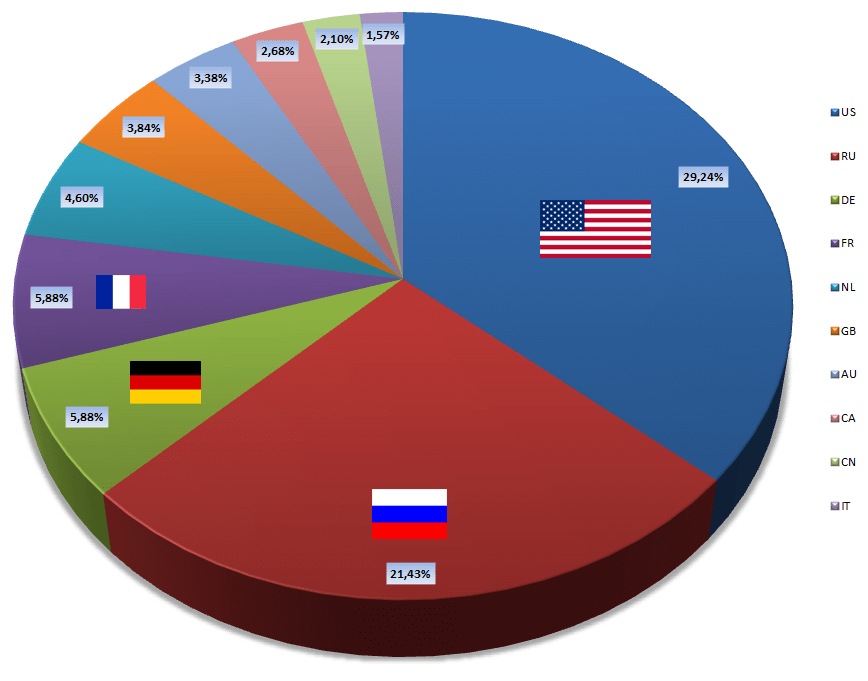
I also see IP's being used that do not match any record found on Internet.
I wonder, who is the owner to these IP's? Which country's Intelligence community owns these adresses?
Do you know? Please let me know.
185.222.209.42, 185.222.210.33, 185.222.211.10, 185.222.211.66 and 185.222.211.146 - impossible to find anything about these anywhere. Most trace to east coast US, some trace to China and Russia. There are many more IP's, adresses without owner (as it seems).
And why are they trying to hack the Ai server? So many questions.
It is sad to see Internet becoming a black box community where criminals can roam freely. There is no police governing it anymore, I thought Interpol would do that, but they are not interested in investigating this kind of activity. Please contact me and let me
know if there are other organizations out there who would be interested to find out the true sources behind those attacks and shut them down. I have thousands of IP's which I can share with anyone interested.
Whistle blowers out there, please email if you know more or have inside information - info@ethertechnologies.com. Thanks!
Update 2022-02-10 by Per Callmin
Regarding Updates
Unfortunately, with every new update the network gets bombarded by Russian and Chinese rouge companies and government agencies trying to hack our servers. For this reason, unfortunately, no more information will be posted here.
I have material for a new movie but not so much time to edit it, but I hope to be able to finalize it soon.
If you are interested in recent development of Skydancer, drop an email to info@ethertechnologies.com for recent updates.
What are your thoughts about Ai in general? Do you want to get involved with SkyDancer development? Send me an email at info@ethertechnologies.com and let's start a conversation.
|
